Paper Review: If the Model Doesn’t Have to Carry It, Move It Out
Paper: Externalization in LLM Agents: A Unified Review of Memory, Skills, Protocols and Harness Engineering ArXiv: 2604.08224 | Shanghai Jiao Tong, Sun Yat-Sen, CMU, and others | April 2026 | 54 pages
Why this paper
“The harness matters more than the model.” We’ve been hearing this for two years now. Same model, different harness, 17-point gap on SWE-bench. Anthropic cuts Claude Code’s thinking depth, the whole community loses it. Everyone’s saying the same thing: stop obsessing over the model, look at the environment. But it’s all been experience and metaphor — harness as operating system, harness as guardrails — nobody’s given a ground-up explanation for why moving things out of the model makes agents more reliable.
This survey does exactly that. It uses cognitive science to give a unified account: Memory, Skills, Protocols, and Harness — four engineering trends that look independent — are all driven by the same underlying logic.
The core idea: externalization changes the task, not the capability
The paper’s theoretical anchor is Donald Norman’s concept of “cognitive artifacts.” Norman’s key insight is counterintuitive: external tools don’t amplify your internal abilities. They turn the task into a different task.
A grocery list is the clearest example. The list doesn’t improve your memory. What it does is turn “recall what you need to buy” (hard) into “look at what’s written on the paper” (easy). The nature of the task changes — from recall to recognition.
LLM agent externalization works the same way. The paper identifies three recurring problems that bare models run into, each addressed by a different form of externalization:
The continuity problem. Context windows are finite, session memory is weak or nonexistent. Every new session is a partial amnesia event. Consider a SWE agent implementing a feature in a large repo — it needs to remember repo structure, project conventions, work-in-progress state, past mistakes. Without externalized memory, all of this has to fit in the prompt. When the prompt fills up or the session breaks, the context is gone. With memory, the model no longer needs to “remember” what it once knew — it retrieves from persistent storage. Recall becomes retrieval.
The variance problem. Multi-step workflows get re-derived every time instead of being consistently executed. Same prompt, five steps today, three tomorrow, skipping the validation step the day after. The model isn’t incapable — it’s just unstable when improvising from scratch every time. With skills, the agent stops inventing workflows and starts selecting and composing verified ones. Generation becomes composition.
The coordination problem. Interactions with external tools, services, and collaborators are fragile. Every tool call requires guessing parameter formats, return structures, error handling patterns. With protocols, this open-ended reasoning gets replaced by filling in fields within explicit contracts. Ad hoc negotiation becomes structured exchange.
The common thread: externalization doesn’t give the model more information. It changes the problem the model is asked to solve.
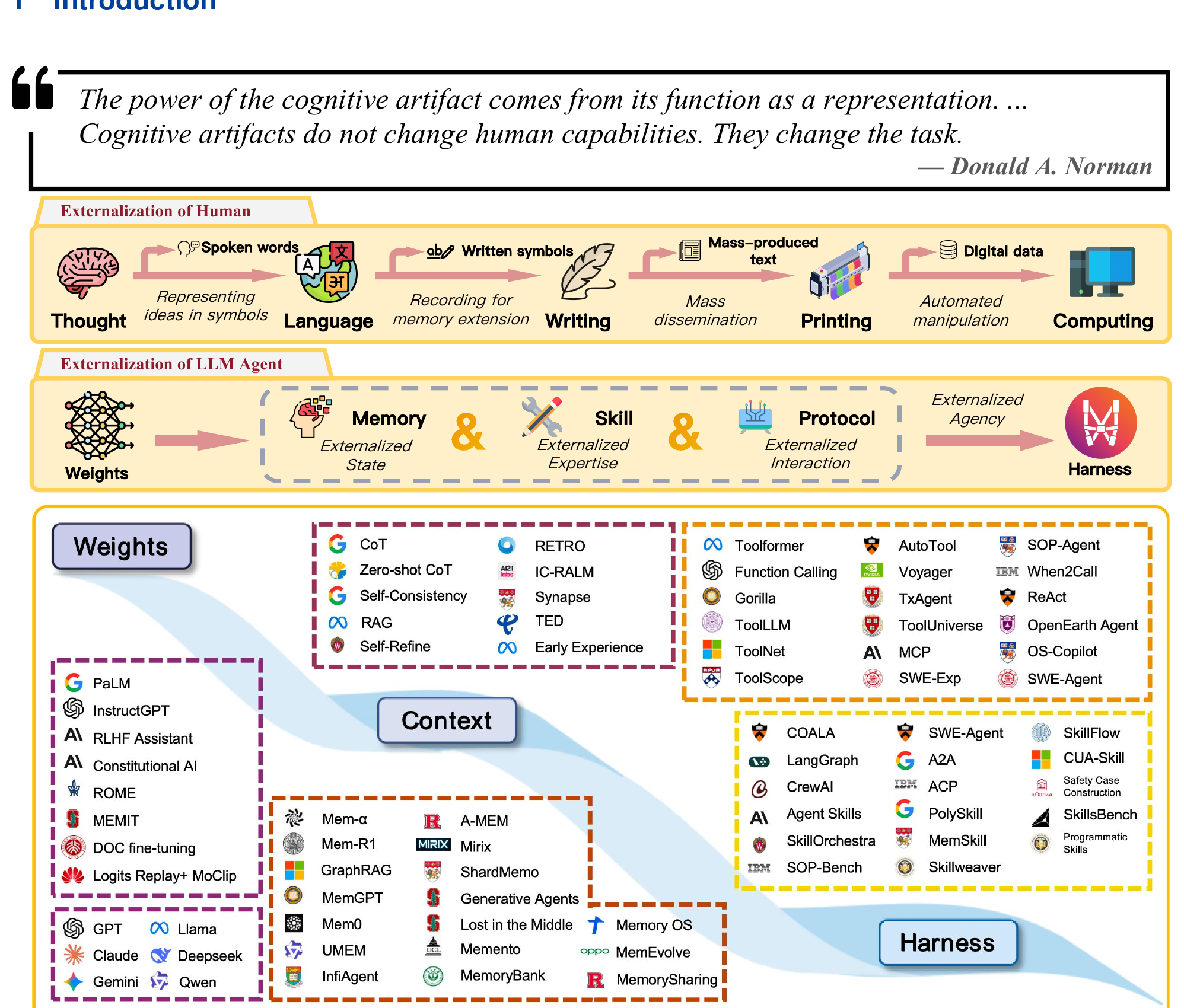 Fig 1: Top — the arc of human cognitive externalization (Thought → Language → Writing → Printing → Computing). Middle — the LLM agent parallel (Weights → Memory/Skills/Protocols → Harness). Bottom — the literature landscape, organized by Weights, Context, and Harness layers.
Fig 1: Top — the arc of human cognitive externalization (Thought → Language → Writing → Printing → Computing). Middle — the LLM agent parallel (Weights → Memory/Skills/Protocols → Harness). Bottom — the literature landscape, organized by Weights, Context, and Harness layers.
Three eras: from changing the model to changing the environment
The paper maps the 2022–2026 evolution into three eras. They don’t replace each other — all three coexist. What changes is where developers spend their marginal engineering effort.
Weights era (2022 peak): Capability equals parameters. Scaling laws, fine-tuning, RLHF, DPO. Fast inference, compact deployment, strong cross-task generalization. But knowledge and procedures are tightly coupled into static artifacts — updating a single fact risks catastrophic forgetting. And one set of weights serves millions of different users with no way to personalize at the parameter level.
Context era (2023–2024): Attention shifts from modifying the model to designing the input. Prompt engineering shows you can dramatically change behavior without touching weights. ReAct interleaves reasoning with tool calls — pure prompting produces agent-like behavior. RAG injects external documents dynamically. In Norman’s terms, the question shifts from “does the model know this fact?” (recall) to “the fact is already in context — can the model use it?” (recognition). But context windows are finite and expensive, lost-in-the-middle is real, and every new session is still a partial amnesia event.
Harness era (2025–2026): When context saturates and prompt templates get unwieldy, engineering attention moves to “what environment should the model run in?” Auto-GPT and BabyAGI were early explorations; SWE-Agent, OpenHands, Deep Research, and LangGraph matured the pattern. The recurring theme: reliability problems get solved by changing the environment, not by tweaking prompts.
Memory: it’s not how much you store, it’s what you retrieve
The memory chapter is probably the most thorough part of the paper. It breaks agent memory into four layers — not by technical implementation, but by what cognitive burden each layer externalizes:
-
Working Context: The active intermediate state of the current task. Open files, temporary variables, active hypotheses, partial plans. Changes fastest. Without externalization, it vanishes when the context window resets. Coding agents handle this by writing drafts, terminal state, and workspace snapshots outside the prompt.
-
Episodic Experience: Past decision points, tool calls, failures, outcomes, reflections. Not just an archive — retrieved episodes serve as concrete precedents that help the agent avoid repeating mistakes. Reflexion is a good example: it stores reflective summaries of failed attempts and pulls them up for similar future tasks.
-
Semantic Knowledge: Abstractions that hold across cases. Domain facts, general heuristics, project conventions. The distinction from episodic isn’t just granularity — it’s about what generalizes. Most common form today is RAG corpora, but the trend is agents distilling their own semantic guidance from accumulated traces.
-
Personalized Memory: Stable information about specific users or teams. Preferences, habits, recurring constraints. This can’t be mixed into the agent’s general self-improvement store — user-specific data has different retention and privacy rules.
The paper makes a sharp observation: a system that stores a lot but retrieves poorly presents the wrong problem to the model. The history exists, but the task hasn’t been simplified. By contrast, a system with moderate storage but strong indexing, summarization, and context selection makes downstream reasoning significantly easier. The success metric for memory isn’t “how much is saved” but “is the context for the current decision clear and readable?”
Memory architectures have gone through four generations: monolithic context (everything in the prompt) → retrieval-augmented storage (RAG) → hierarchical management (hot/cold separation like MemGPT) → adaptive systems (retrieval strategies that evolve based on feedback). The shift from storage to control — memory gradually moving from a passive prompt appendix to part of the harness control plane.
Skills: from improvisation to selection
Skill externalization addresses the procedural burden. The model might “know” how to complete a task in principle, but when it re-derives the workflow from scratch every time, behavior is unstable: skipped steps, inconsistent tool usage, wandering stop conditions.
The paper breaks skills into three interlocking components: operational procedures (step structure, dependencies, stop conditions), decision heuristics (what to pick at branch points, when to fall back, what counts as enough evidence), and normative constraints (test requirements, scope limits, access permissions). Procedures provide structure, heuristics provide local strategy, constraints provide acceptable boundaries. Only when all three are specified does a skill become genuinely reusable across tasks.
Skill systems evolved through three stages:
Stage one: atomic execution primitives. Models learned to call tools reliably — constructing parameters, integrating results. Toolformer is the representative work. Stable access to individual actions, but the unit is an API call, not a skill.
Stage two: large-scale tool selection. As the number of available tools grew, the problem shifted from “can we call it” to “which one do we call.” Gorilla, ToolLLM, and others showed models can search and rank across large tool collections. Scalable selection, but the unit is still a tool, not a process.
Stage three: skills as packaged expertise. The question becomes “can the know-how needed to complete a class of tasks be packaged as a reusable capability unit?” Voyager explored this in Minecraft — through exploration, execution feedback, and self-verification, it built a growing library of code-level skills. The key shift isn’t doing more things — it’s that capabilities change form: from scattered tool calls to packaged knowledge that can be loaded, reused, and composed across tasks.
The paper highlights progressive disclosure as a design pattern: discovering a skill doesn’t mean its full content should be dumped into context immediately. Long context doesn’t reliably translate to better performance — detailed instructions can become reasoning noise. So you load in layers: the minimum layer exposes just a name and short description; deeper layers reveal applicability conditions and constraints; the deepest layer loads the full procedural detail. Claude Code’s skill system is the paper’s primary example of this pattern in production.
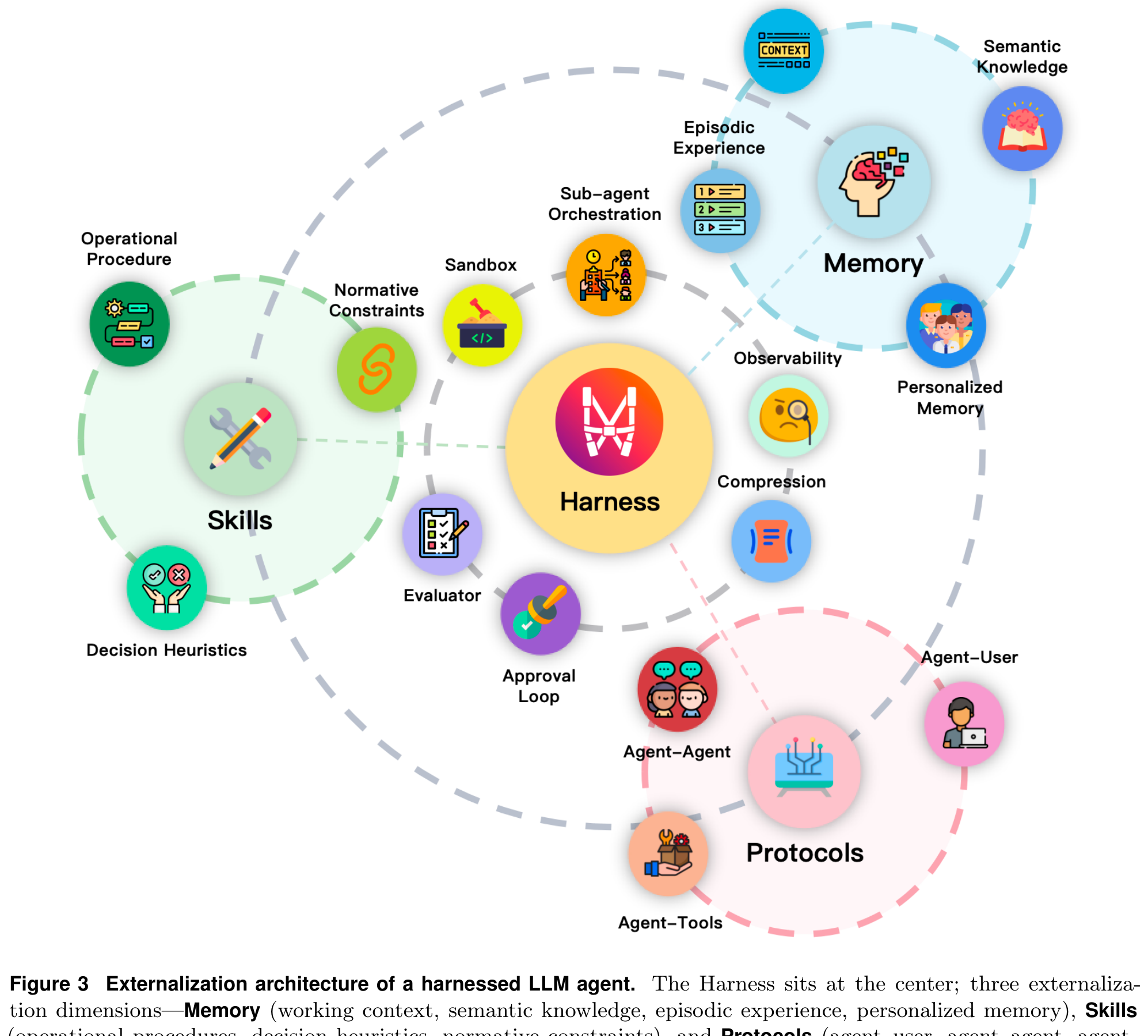 Fig 3: The full externalization architecture. Harness at the center, coordinating Memory, Skills, and Protocols. Sandbox, Observability, Evaluator, Approval Loop, and other operational elements surround it.
Fig 3: The full externalization architecture. Harness at the center, coordinating Memory, Skills, and Protocols. Sandbox, Observability, Evaluator, Approval Loop, and other operational elements surround it.
Protocols: stop making the model guess how to talk
The protocol chapter has one argument that really sticks: of the three forms of externalization, protocols are the most powerful because they remove an entire class of problems from the model’s reasoning burden.
Without protocols, every interaction with the outside world is an open-ended reasoning exercise: guess the parameter format, guess the return structure, infer lifecycle semantics, hope the other side interprets the result correctly. The model isn’t bad at this — it’s that these problems shouldn’t need to be re-solved by reasoning every single time. With protocols, they become specs in black and white: parameter names, types, return structures are all declared. The model just fills in the blanks.
Take MCP as an example. Before standardization, every new tool required custom integration logic: what does this API look like, how do I call it, how do I parse the response. MCP standardizes this: tools declare “here’s what I can do, here are my parameters, here’s what I return,” and agents discover and call them through a uniform interface. Tool integration goes from “custom work for each one” to “plug and play.”
The paper also draws a boundary that’s easy to blur: protocols like MCP specify how tools are described and called. They don’t specify what multi-step process to follow when using those tools (that’s skills), and they don’t maintain cognitive continuity across sessions (that’s memory). Each manages its own domain; the harness coordinates between them.
On multi-agent protocols, the paper surveys A2A (Google) for structured capability discovery and task delegation between agents; ACP (IBM) for lightweight adoption via REST/HTTP; and ANP for decentralized cross-domain agent discovery. Different layers, same pattern: turning coordination from implicit guesswork into explicit, inspectable structure.
Module dynamics: six coupling flows
One of the paper’s most interesting analyses maps out six bidirectional coupling flows between Memory, Skills, and Protocols. These modules don’t run in isolation — real systems get their power from the interactions.
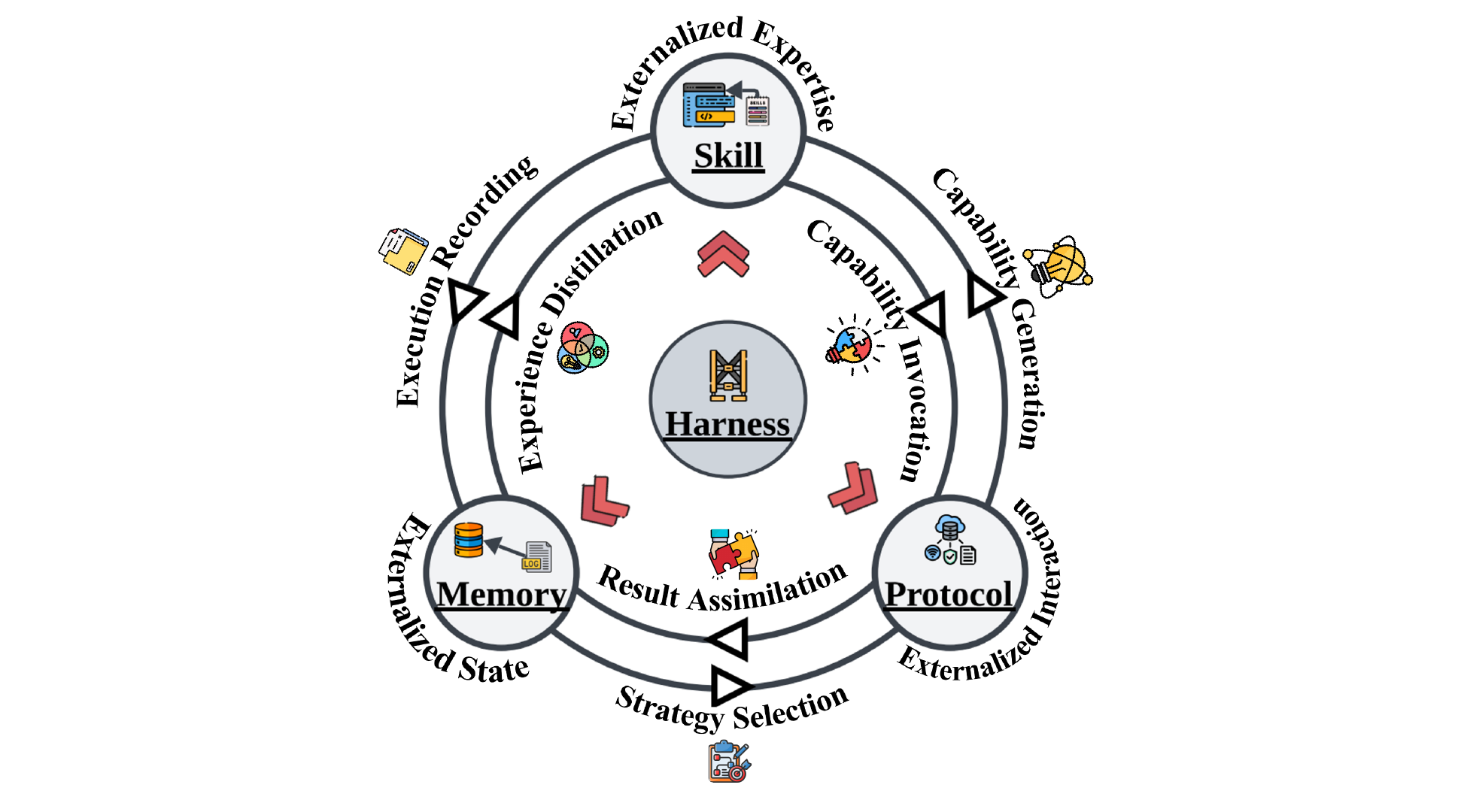 Fig 8: Three externalization modules coupled through six flows, with the Harness coordinating at the center.
Fig 8: Three externalization modules coupled through six flows, with the Harness coordinating at the center.
A few worth unpacking:
Memory → Skill (experience distillation): Recurring success patterns get abstracted into reusable procedures. Voyager is the canonical example: episodic traces from repeated Minecraft exploration get refined into a growing code-level skill library. Memory isn’t just storing what happened — it’s the evidence base the harness uses to decide “what experience is worth promoting to a standard procedure.” The quality of distillation (what actually generalizes vs. what’s a situational fluke) determines the reliability of the entire skill layer.
Skill → Memory (execution recording): The reverse flow. Every skill execution produces traces, intermediate failures, runtime adjustments. If these aren’t written back to memory, the system can’t verify which skills are still reliable and which need revision. Break this flow, and the distillation above runs on increasingly stale evidence.
Protocol → Skill (capability generation): Easy to miss but important. Once interfaces are standardized, codifying best practices for using them becomes dramatically easier. MCP doesn’t just make tools callable — it expands the surface area for writing new skills. Every new stable interface is a potential seed for a family of reusable skills. Protocol standardization doesn’t just consume skills — it actively grows the space where new skills can be written.
The paper also identifies three system-level emergent properties:
-
Self-reinforcing loops: Better memory → better skill distillation → richer execution traces → better memory. Positive feedback accelerates capability growth, but also amplifies errors. A poisoned memory entry produces a flawed skill, whose execution traces further pollute memory — cascading to the point where no single module’s quality control can break the cycle. That’s when harness-level intervention is needed.
-
Context competition: All three modules share the same scarce resource — the context window. Expanding one module’s footprint necessarily compresses the others. The harness has to manage allocation dynamically.
-
Timescale mismatch: Protocol interactions are typically fast and synchronous. Skill loading happens at task boundaries. Memory distillation unfolds across sessions. A harness optimized for fast loops (tool execution speed) may neglect the slow loops (long-term capability growth).
The evaluation blind spot: giving the model credit for harness work
The paper’s final section pokes at a real sore spot in the evaluation world: current benchmarks systematically undervalue the contribution of externalization infrastructure.
The logic is simple. When we say “model X scores Y% on SWE-bench,” how much of that Y% comes from model capability and how much from harness design? Benchmarks report final pass rates — there’s no way to split the attribution. Improved reliability from better memory retrieval, more precise skill loading, or tighter execution governance just shows up as a higher score, with all credit going to the model.
The paper suggests several directions: ablation studies (remove harness components one by one and measure degradation), cross-model transfer tests (fix the harness, swap in different models, see how much the score fluctuates), and longitudinal reliability metrics (track across multiple sessions instead of just single-turn completion).
Until these methods mature, the field will keep attributing externalization design achievements to model intelligence.
Takeaway
This paper offers a practical mental model: when you hit an agent reliability problem, ask “should this burden live inside the model or outside it?” before reaching for a bigger model. What models are good at — flexible synthesis, reasoning over provided information, interpreting context — let the model do. What models aren’t good at — stable long-term memory, procedural consistency, governed interaction with external systems — move it out.
A better agent isn’t a better reasoner. It’s a better-organized cognitive system.
Paper link: arXiv 2604.08224