论文粗读:能往外搬的,别让 Agent 自己扛
论文:Externalization in LLM Agents: A Unified Review of Memory, Skills, Protocols and Harness Engineering ArXiv: 2604.08224 | 上海交大、中山大学、CMU 等 21 位作者 | 2026 年 4 月 | 54 页
为什么读这篇
Harness 比模型重要,这话这两年听太多了。SWE-bench 上同一个模型换不同 harness 差 17 题,Claude Code 的 thinking 被砍之后整个社区炸锅。大家都在讲同一件事:别光盯着模型,得看环境。但说来说去都是经验和隐喻,harness 是操作系统,harness 是围墙,没人从底层解释过”为什么把东西搬出模型就能变好”。
这篇 54 页的综述干的就是这个事。它从认知科学的角度给出了一个统一解释:Memory、Skills、Protocols、Harness,这几个看着各管各的工程趋势,背后其实是同一个逻辑在驱动。
核心概念:外化改变的不是能力,是任务本身
论文拿 Donald Norman 的”认知制品”(cognitive artifacts)理论做支点。Norman 有个很反直觉的观察:外部工具不是放大你的内部能力,而是把任务变成了另一个任务。
购物清单就是最好的例子。清单不是让你记忆力变好了。它做的事情是:把”回忆要买什么”这个困难任务,变成”看一眼纸上写了什么”这个简单任务。任务的性质变了,从回忆(recall)变成了识别(recognition)。
LLM Agent 的外化是同一回事。论文梳理了裸模型反复踩的三个坑,每个坑对应一种外化方式:
连续性问题。 上下文窗口有限,session memory 弱或者干脆没有。Agent 每开一个新 session 都是部分失忆的开始。论文举了个例子:一个 SWE agent 在大仓库中实现功能,它需要记住仓库结构、项目惯例、工作进度、之前踩过的坑。没有外化 memory 的时候,这些全靠塞进 prompt。prompt 一满或者 session 一断,这些上下文就丢了。有了 memory,模型不再需要”回忆”过去知道什么,而是从持久化存储中检索。回忆变成了检索(recall → retrieval)。
方差问题。 多步骤流程每次都被重新推导,而不是被一致执行。同一个 prompt,今天可能分五步做,明天分三步,后天跳过关键的验证步骤。模型不是不知道该怎么做,而是每次从头即兴创作的时候不够稳定。有了 skill,Agent 不需要每次发明工作流,而是选择和组合已验证的流程。从头生成变成了选择组合(generation → composition)。
协调问题。 与外部工具、服务、协作者的交互是脆弱的。模型每次调工具都要猜参数格式、猜返回结构、猜错误处理方式。有了 protocol,这些开放式的推理被替换成了在显式契约内填字段。临场协商变成了结构化交换(ad hoc → structured exchange)。
三种外化的共同点:不是给模型加了更多信息,而是模型被要求解决的问题变了。
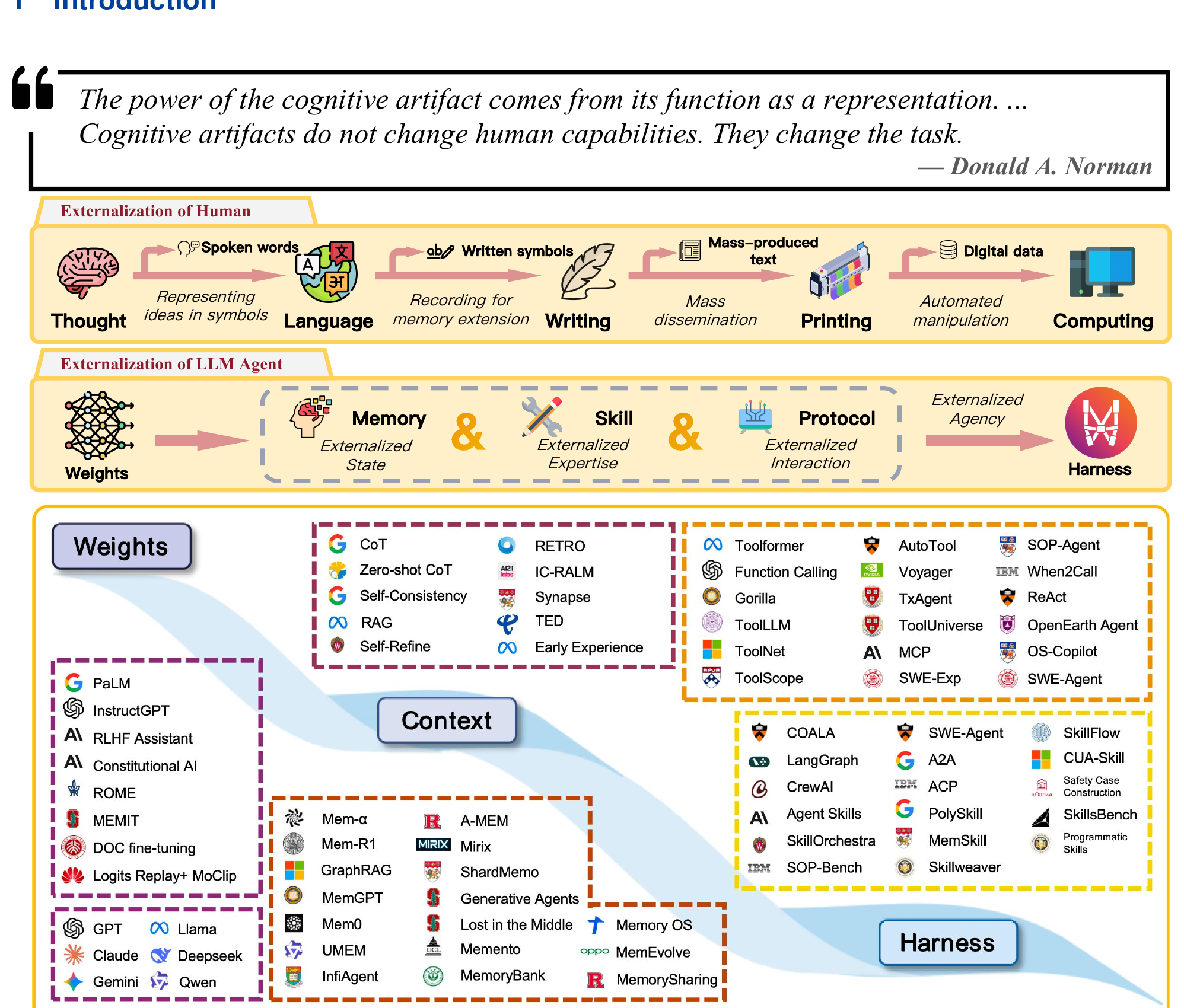 Fig 1: 上半是人类认知外化的弧线(思想 → 语言 → 文字 → 印刷 → 计算),中间是 LLM Agent 的对应路径(Weights → Memory/Skills/Protocols → Harness),下半是文献全景,按 Weights、Context、Harness 三层分类。
Fig 1: 上半是人类认知外化的弧线(思想 → 语言 → 文字 → 印刷 → 计算),中间是 LLM Agent 的对应路径(Weights → Memory/Skills/Protocols → Harness),下半是文献全景,按 Weights、Context、Harness 三层分类。
三个阶段:从改模型到改环境
论文把 2022 到 2026 的社区演变归纳为三个阶段。不是说前一个阶段结束了后一个才开始,三层一直共存,变的是开发者把边际精力花在哪里。
Weights 阶段(2022 为主): 能力等于权重。Scaling laws 建立了参数量、数据量和损失之间可预测的关系。Fine-tuning、RLHF、DPO 进一步塑造行为。好处是推理快、部署紧凑、跨任务泛化强。坏处是知识和过程紧密耦合在静态参数里,想更新一个事实就得 retrain,有灾难性遗忘的风险。更关键的是:一套权重服务数百万不同用户,没法在参数层面做个性化。
Context 阶段(2023-2024): 注意力从改模型转向设计输入。Prompt engineering 证明不改权重就能大幅改变行为。ReAct 把推理和工具调用交织在一起,纯 prompting 就能产生类 agent 的行为。RAG 动态注入外部文档。Norman 的视角来看,问题从”模型知道这个事实吗”(回忆/recall)变成了”事实已经在上下文里了,模型能用吗”(识别/recognition)。但上下文窗口有限且昂贵,“中间遗忘”(lost in the middle)现象严重,每个新 session 依然是部分失忆的开始。
Harness 阶段(2025-2026): 当 context 饱和、prompt 模板越来越笨重,工程注意力转向”模型应该在什么环境里运行”。Auto-GPT 和 BabyAGI 是早期探索,SWE-Agent、OpenHands、Deep Research、LangGraph 逐步成熟。一个反复出现的模式是:可靠性问题越来越多地通过改变环境来解决,而不是在 prompt 上修修补补。
Memory:不是存多少,是检索出什么
Memory 这一章大概是论文写得最扎实的部分。它把 agent 的 memory 拆成四层,不是按技术实现分,而是按”外化了什么认知负担”分:
-
Working Context(工作上下文): 当前任务的活跃中间状态。打开的文件、临时变量、活跃假设、部分计划。变化最快,不外化的话随上下文窗口重置就没了。Coding agent 通过把 drafts、terminal 状态、workspace 快照写到 prompt 之外来实现恢复。
-
Episodic Experience(情景经验): 之前跑过的决策点、工具调用、失败、结果、反思。不只是归档,检索到的历史片段可以作为具体先例帮 agent 避免重蹈覆辙。Reflexion 是个典型:它把失败尝试的反思摘要存起来,下次类似任务直接调出来。
-
Semantic Knowledge(语义知识): 超越任何单个事件的抽象。领域事实、通用启发式、项目惯例。和情景经验的区别不仅是粒度,而是”什么东西跨案例仍然成立”。目前最常见的形式是 RAG 语料库,趋势是 agent 越来越多地从积累的轨迹中自己蒸馏出语义指导。
-
Personalized Memory(个性化记忆): 关于特定用户或团队的稳定信息。偏好、习惯、反复出现的约束。这部分不能混进 agent 的通用自我改进存储,因为用户特定的数据有不同的保留和隐私规则。
论文有一个判断很到位:存得多但检索弱的系统,给模型呈现的是错误的问题。 历史是存下来了,但任务没有被简化。相反,一个存储适度但索引、摘要、上下文选择都强的系统,能让下游推理显著变容易。Memory 的成功标准不是”保存了多少”,而是”当前这一步决策的上下文是否清晰可读”。
memory 架构也经历了四代演进:单体上下文(全塞 prompt 里)→ 带检索的外部存储(RAG)→ 分层管理(MemGPT 那种热/冷分离)→ 自适应系统(检索策略本身可以根据反馈演化)。从存储到控制的转变,memory 逐步从 prompt 的被动附录变成 harness 控制面的一部分。
Skill:从即兴发明到选择和遵循
Skill 外化解决的是程序性负担。模型可能原则上”知道”怎么完成一个任务,但每次从头推导工作流的时候,行为不够稳定:跳步骤、工具使用不一致、停止条件飘忽不定。
论文把 skill 拆成三个相互关联的部分:操作过程(步骤骨架、依赖、停止条件)、决策启发(分支处选什么、何时回退、什么证据够了)、规范约束(测试要求、范围限制、访问权限)。三者合起来,操作过程提供结构,决策启发提供局部策略,规范约束提供可接受边界。只有三者都充分指定,skill 才真正可跨任务复用。
Skill 系统的演化经历了三个阶段,论文讲得很清楚:
阶段一:原子执行原语。 模型学会了稳定调用工具,能构造参数、整合结果。Toolformer 是代表。成就是稳定访问单个动作,但单元只是 API 调用,不是 skill。
阶段二:大规模工具选择。 工具数量增长后,问题从”能不能调”变成”调哪个”。Gorilla、ToolLLM 等展示模型能在大集合中检索和排序。关键进步是可扩展的选择能力,但单元仍然是工具而不是过程。
阶段三:Skill 作为打包的专业知识。 核心问题变成”完成一类任务所需的实操经验(know-how)能否被打包为可复用的能力单元”。Voyager 在 Minecraft 中通过探索、执行反馈、自验证,产生不断增长的代码级 skill 库。这个变化的关键不在于能做更多事,而在于能力的存在形式变了:从散落的工具调用,变成了可以加载、复用、跨任务组合的打包知识。
论文特别提到了渐进披露(progressive disclosure)这个设计模式:发现一个 skill 不意味着它的全部内容应该立刻灌入上下文。长上下文不能可靠转化为更好的性能,详细指令反而可能变成推理噪声。所以采用分层加载:最小层只暴露名字和简短描述,更深层暴露适用条件和约束,最深层才加载完整的过程细节。Claude Code 的 skill 系统是论文提到的这种设计的典型工业实现。
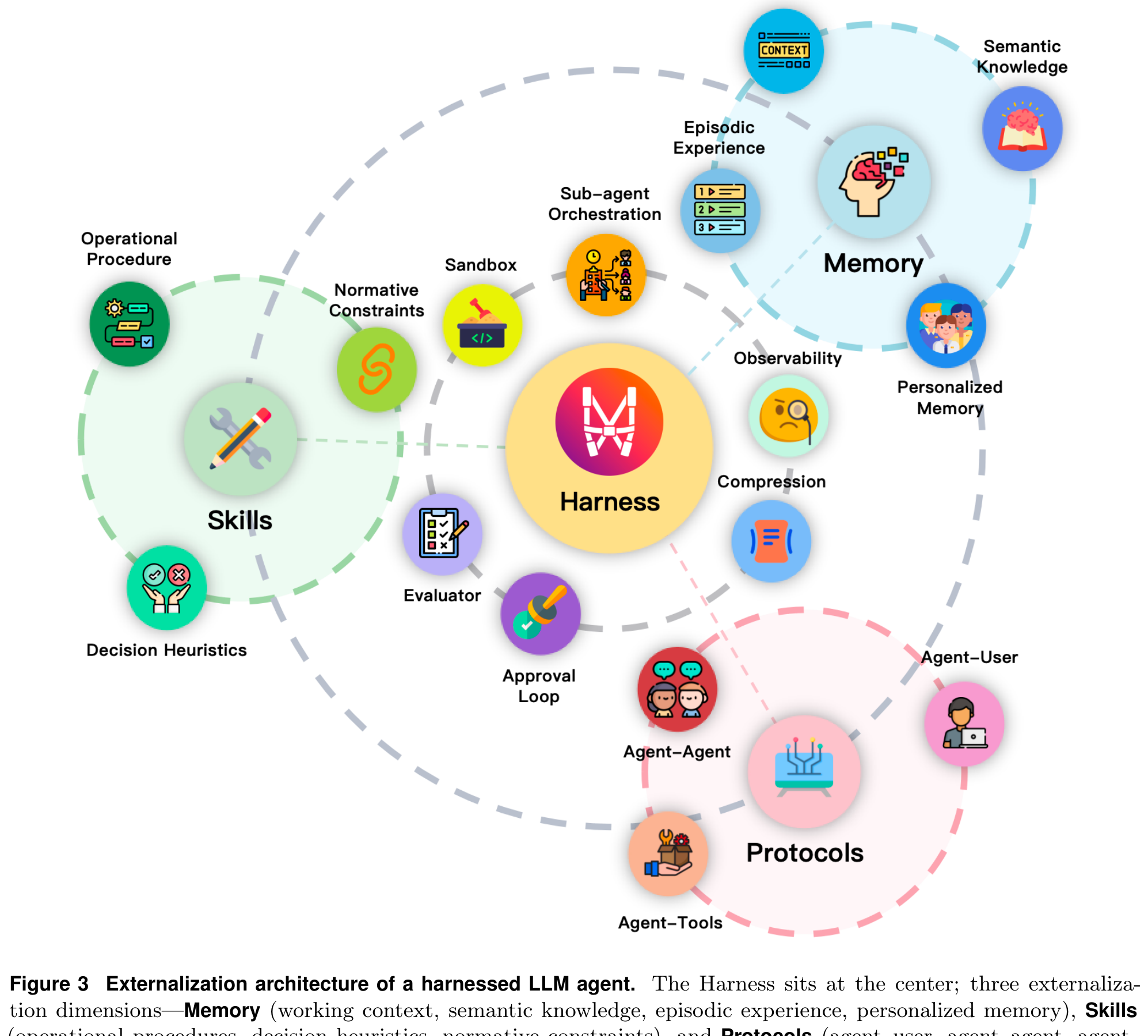 Fig 3: 完整的外化架构。Harness 居中协调,Memory、Skills、Protocols 三个维度环绕。Sandbox、Observability、Evaluator、Approval Loop 等是 Harness 的操作元素。
Fig 3: 完整的外化架构。Harness 居中协调,Memory、Skills、Protocols 三个维度环绕。Sandbox、Observability、Evaluator、Approval Loop 等是 Harness 的操作元素。
Protocol:让模型不用猜怎么说话
Protocol 那一章有个观点很有意思:在三种外化里,protocol 是效果最猛的,因为它直接把一整类问题从模型的思考负担里拿走了。
什么意思?没有协议的时候,模型每次调一个外部工具,都得自己琢磨:这个 API 的参数叫什么、按什么顺序传、返回的东西长什么样、出错了怎么处理。每次调用都是一次猜谜。模型不是猜不到,而是这些东西本来就不该靠猜。有了协议,这些全变成了白纸黑字的规格:参数名、类型、返回结构都写好了,模型照着填就行。
拿 MCP 举例。以前每接入一个新工具,都得写一套定制的集成逻辑:这个工具的 API 长什么样、怎么调、返回值怎么解析。MCP 把这件事标准化了:工具自己声明”我能做什么、参数是什么、返回什么”,agent 按统一的方式发现和调用。工具接入从”每个都得单独对接”变成了”插上就能用”。
论文还厘清了一个容易混淆的边界:MCP 这类协议管的是”怎么描述和调用工具”,不管”用这些工具该走什么流程”(那是 skill 的事),也不管”上次聊到哪了”(那是 memory 的事)。三者各管各的,通过 harness 协调。
多 agent 协作方面,论文分析了几个协议:A2A(Google)让 agent 之间能互相发现对方的能力、分配任务、追踪进度;ACP(IBM)走轻量路线,用 REST/HTTP 降低接入门槛;ANP 推得更远,做去中心化的跨域 agent 发现。层次不同,但共同点是一样的:把 agent 之间的协调从”各猜各的”变成”有章可循”。
模块之间的动力学:六条耦合流
论文最有意思的分析之一,是画出了 Memory、Skills、Protocols 之间的六条双向耦合流。这三个模块不是各自独立运转的,真实系统的力量来自它们之间的交互。
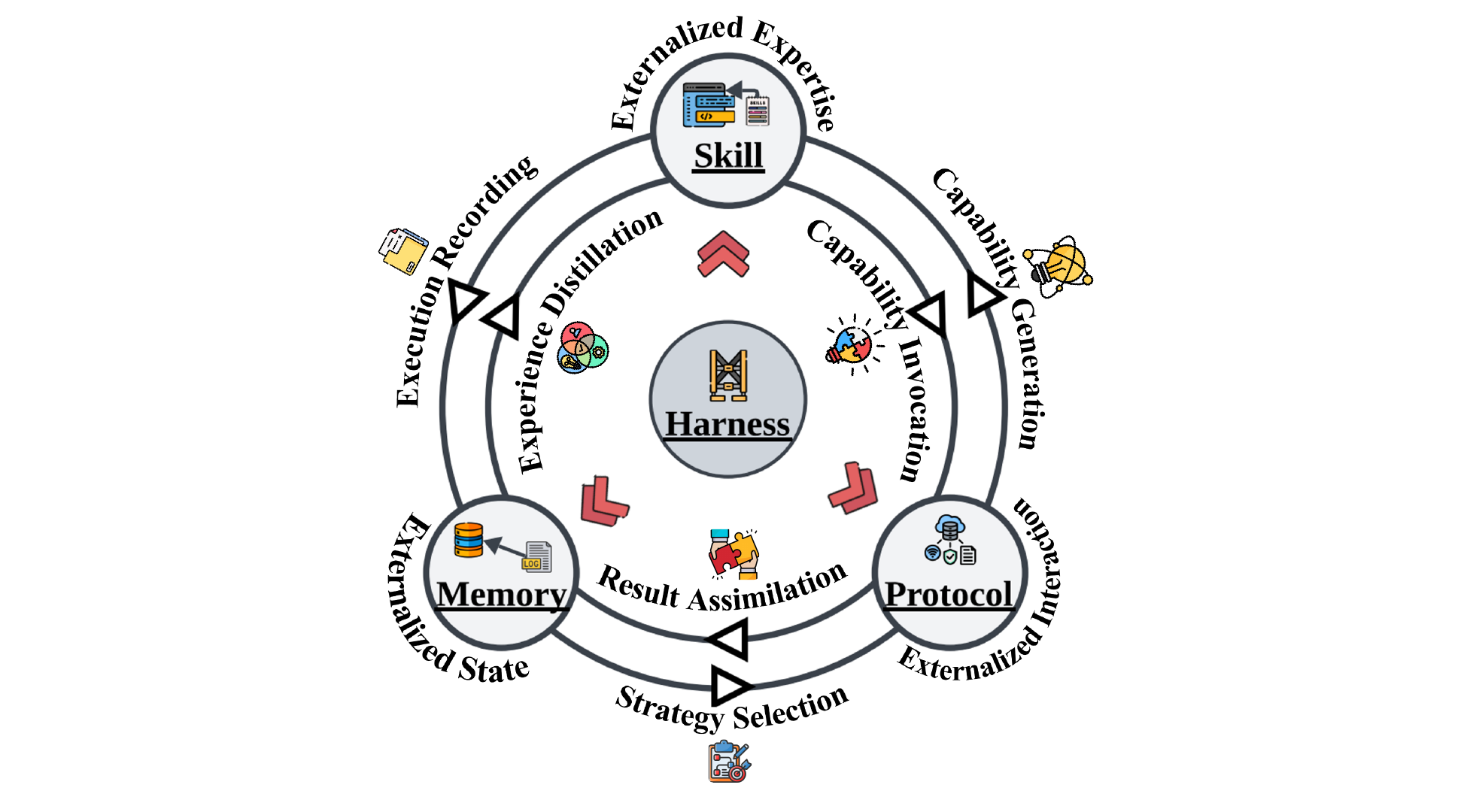 Fig 8: 三个外化模块通过六条流相互耦合,Harness 居中协调。
Fig 8: 三个外化模块通过六条流相互耦合,Harness 居中协调。
几条特别值得展开的:
Memory → Skill(经验蒸馏): 重复出现的成功轨迹被抽象为可复用过程。Voyager 就是典型:在 Minecraft 中反复探索产生的情景轨迹(episodic trace),被提炼成一个不断增长的代码级 skill 库。Memory 不只是存过去发生了什么,更是 harness 判断”什么经验值得提升为标准流程”的证据来源。蒸馏的质量(什么能泛化、什么只是特定情境下的巧合)决定了整个 skill 层的可靠性。
Skill → Memory(执行记录): 反向流。每次 skill 执行都产生执行轨迹、中间失败、运行时微调。如果这些不写回 memory,系统就无法验证哪些 skill 还可靠、哪些该修订。这条流断了,上面那条经验蒸馏就是在越来越过时的证据上运作。
Protocol → Skill(能力生成): 这条流容易被忽视但很重要。接口标准化之后,编纂使用这些接口的最佳实践变得大幅容易。MCP 不仅让工具可调用,还扩展了可以编写新 skill 的表面。每个新的稳定接口都是一族可复用 skill 的潜在种子。Protocol 标准化不仅消费 skills,还主动扩展了可编写新 skill 的空间。
论文还指出了三个系统级的涌现性质:
-
自我强化循环: 更好的 memory → 更好的 skill 蒸馏 → 更丰富的执行轨迹 → 更好的 memory。正反馈加速能力增长,但也放大错误。有毒的 memory 条目导致有缺陷的 skill,执行轨迹进一步污染 memory,级联到单个模块的质量控制无法中断的程度。这时候必须靠 harness 级的干预来打断。
-
上下文竞争: 三个模块共享同一个稀缺资源,上下文窗口。扩展一个模块的占用必然压缩其他模块的空间。Harness 必须动态管理分配。
-
时间尺度差异: 协议交互通常是快速同步的,skill 加载在任务边界发生,memory 蒸馏跨 session 展开。优化快循环(工具执行速度)的 harness 可能忽略慢循环(长期能力增长)。
评估盲区:把 harness 的功劳算在模型头上
论文最后捅了一个评估领域的软肋:现在的 benchmark 系统性地低估了外化基础设施的贡献。
逻辑很简单:我们说”模型 X 在 SWE-bench 上得分 Y%“的时候,这个 Y% 里有多少来自模型能力,多少来自 harness 设计?benchmark 只报告最终通过率,完全没法拆开归因。一个通过更好 memory 检索、更精确 skill 加载、更紧执行治理提升的可靠性,只会表现为更高的分数,但功劳全算在模型头上。
论文建议了几个方向:消融研究(把 harness 组件一个一个拿掉,看退化多少)、跨模型迁移测试(固定 harness 换不同模型,看分数波动多大)、长期可靠性指标(跨多 session 追踪,不只看单轮完成率)。
在这些方法成熟之前,行业会持续把属于外化设计的成就归因于模型智能。
读完的一些想法
这篇论文给了一个很实用的思维框架:遇到 agent 可靠性问题,先问”这个负担应该放在模型里还是模型外面”,别第一反应就换更大的模型。模型擅长的事(灵活综合、对提供的信息做推理、解释上下文),让模型做。模型不擅长的事(稳定的长期记忆、程序可重复性、与外部系统的受治理交互),往外搬。
更好的 agent 不是更好的推理器,是更好地组织的认知系统。
论文链接: arXiv 2604.08224